Jede und jeder, die bzw. der eine neue Arbeitsstelle antritt, kennt das: Neue Prozesse, neue Regeln und vor allem neue Begrifflichkeiten und Abkürzungen. Die neuen Kollegen sprechen eine „wunderliche“ Sprache mit Spezialbegriffen. Aber alle schon länger in der Organisation arbeitenden Personen scheinen virtuos mit den Begriffen umzugehen und sich zu verstehen. Neue und Außenstehende verstehen evtl. nur Teile oder haben vielleicht auch ein falsches Verständnis von verwendeten Begriffen. Grund dafür kann sein, dass sie deren Bedeutung aus ihrem vorigen Umfeld anwenden – und diese nicht passt.
Manche Organisationen haben fast eine eigene Sprache oder zumindest eine eigene Begriffswelt etabliert. Für die „Eingeweihten“ ist alles klar, alle „Neuen“ und von außen kommenden Personen können nicht mitreden.
Glossar zur zentralen und eindeutigen Begriffserklärung
Um hier Transparenz zu schaffen, kann der Aufbau und die dauerhafte Pflege einer Übersicht von Begriffen und Abkürzungen sowie deren Erklärung hilfreich sein. Solch eine Übersicht können wir als „Glossar“ oder – im Geschäftsumfeld – als „Business Glossar“ (englisch: business glossary) bezeichnen.
Wikipedia definiert ein Glossar als „…eine Liste von Wörtern mit beigefügten Bedeutungserklärungen oder Übersetzungen. […] Im erweiterten Sinn wird ein Glossar auch Begriffserklärung genannt (im Unterschied zu einer Begriffsklärung). Insbesondere wenn es um die Beschreibung oder Erklärung einzelner Begriffe geht, wird ein Glossar auch als (Begriffs-)Abgrenzung oder als Definition bezeichnet.“
Was soll ein Business Glossar erreichen?
Die Verwendung eines konzernweiten Business Glossars fördert ein gemeinsames, konsistentes Verständnis von Geschäftsbegriffen und Definition innerhalb der Organisation und ermöglicht allen Anwendern den Zugriff auf die gleichen Informationen mit Begriffen aus Sicht der Fachanwender.
Das Business Glossar definiert somit ein Vokabular von Wörtern und Phrasen oder ein Notationssystem, einschließlich Fachbegriffen, die innerhalb der Organisation genutzt werden. Anfänglich deckt dieses Vokabular nicht alle Themen und Inhalte ab. Die Anwenderinnen und Anwender können nach Inhalten suchen, indem sie vertrautes Geschäftsvokabular und Synonyme verwenden oder effizient in den Definitionen navigieren.
So baut man ein Business Glossar strukturiert auf
Glossareinträge sind eigentlich relativ einfach strukturiert:
- Glossarbegriff: der Begriff als Wort oder mehrere Worte, der erklärt wird
- Erläuterung: Die verbale Beschreibung zu dem Glossarbegriff. Dies kann als Prosa erfolgen, es können ggf. auch Links zu internen oder externen Dokumenten oder Seiten enthalten sein. Eine ausschließliche Erläuterung nur durch Verlinkung anderswo hin halte ich für nicht empfehlenswert, zumindest einige Sätze sollten im Glossar direkt zu finden sein.
Das wäre eigentlich die Grundstruktur. Darüber hinaus protokolliert man auch organisatorische und prozessuale Informationen:
- Datendomäne, zu der dieser Begriff gehört. Die Zuordnung zu Datendomänen (näher erläutert in meinem vorherigen Blog-Beitrag) kann auch nicht eindeutig sein, d. h. ein Begriff wie bspw. „Adresse“ ist sowohl der Kunde- als auch der Lieferant-Datendomäne zuzuordnen.
- Status: nicht geprüft, in Arbeit, freigegeben/bestätigt
- Erstell- und/oder Freigabedatum
- Datum der letzten Prüfung
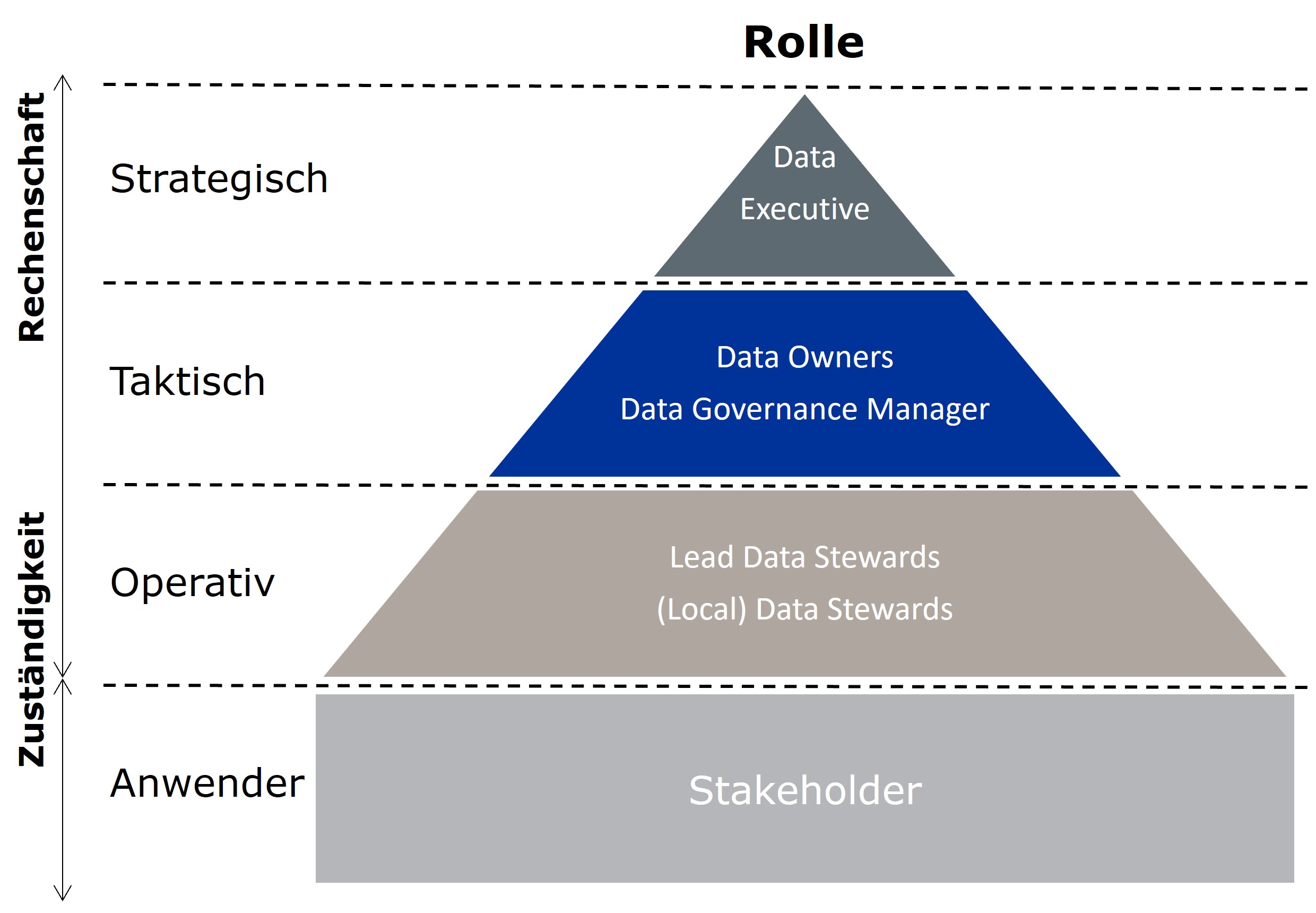
- Geprüft/freigegeben durch: Hier ist m. E. die Verantwortung bei dem/der/den Data Steward(s) der zugeordneten Datendomäne(n) zu sehen. Data Stewards prüfen die Begriffe und deren Erklärung – oder erstellen die Erklärung auch selber – und geben diese frei.
Will eine Organisation ein Business Glossar aufbauen, ist es sinnvoll, zunächst die vorhandenen Erklärungslisten zu sammeln und zu konsolidieren. Viele Mitarbeiterinnen und Mitarbeiter führen für sich selbst Listen mit Begriffserklärungen. Insbesondere neue Mitarbeiterinnen oder Mitarbeiter, die in ein neues Umfeld mit vielen neuen unbekannten Begriffen kommen, erstellen sich solche Listen.
Das Sammeln von Begriffen kann man ggf. durch Wettbewerbe mit kleinen Preisen erfolgreicher machen. Ebenso können neue Mitarbeiterinnen und Mitarbeiter – die natürlich in ihrem Einarbeitungspaket das Business Glossar bekommen haben – das vorhandene Glossar auf Lücken prüfen. „Neulinge“ erkennen oftmals eher die Lücken bzw. fehlende Begriffe, die für „Alteingesessene“ Standard sind und deshalb nicht für das Glossar vorgesehen wurden.
Nach einer gewissen Zeit der Sammlung und Verarbeitung wird ein Business Glossar dann wahrscheinlich stabil werden, d. h. neue Einträge werden seltener. Die regelmäßige Sichtung und Prüfung bestehender Einträge auf Aktualität und Korrektheit ist aber dennoch notwendig.
Erfolgsmessung – auch für ein Business Glossar?
Da es bei und mit Daten immer auch um KPIs und das Messen der Zielerreichung geht, stellt sich diese Anforderung durchaus auch für ein Business Glossar. Um den Nutzen eines Glossars zu messen, verwenden wir Kennzahlen wie etwa die folgenden:
- Anzahl – bzw. besser: Anteil von vollständig beschriebenen Glossar-Begriffen: „Vollständig“ wäre hier eine ausreichend detaillierte Erläuterung – diese Definition von „vollständig“ muss leider vage bleiben, da sie sich m. E. nicht in „Anzahl Worte“ o. ä. messen lässt. Alternativ oder zusätzlich setzen wir auf Interaktion durch die Anwenderinnen und Anwender. Diese bewerten dabei Glossarbegriffe („like“ oder „dislike“ oder andere Wertungen). Dann könnte die Messung wie folgt sein:
- Anzahl – bzw. besser: Anteil von Glossar-Begriffen mit positiver Like-Quote – also Begriffe, die mehr „like“ als „dislike“ haben. Glossar-Einträge, die gar keine Reaktion haben, werden als „negativ“ gewertet.
- Anzahl – bzw. besser: Anteil von geänderten Glossar-Begriffen im Auswertezeitraum: Darüber ist zu erkennen, wie regelmäßig Aktualisierungen von Glossar-Einträgen erfolgen. Nachteil bzw. Herausforderung hierbei ist aber, dass im Grunde Glossar-Begriffe sich nach ihrer Fixierung nicht mehr wirklich ändern sollten. Daher ist eher folgende Kennzahl sinnvoll:
- Durchschnittliches Alter seit letzter Revision der Glossar-Begriffe. „Alter“ wird hier nicht über Anlagedatum, sondern über ein Revisionsdatum ermittelt. Zum Revisionsdatum wird der Glossar-Begriff gesichtet und entweder aktualisiert und bestätigt oder als weiterhin korrekt bestätigt. Darüber wird die kontinuierliche Korrektheit und Aktualität von Begriffen sicher gestellt – und mit dieser Kennzahl gemessen.
Diese Liste erhebt nicht den Anspruch auf Vollständigkeit, sondern soll als Einstieg und Anregung für weitere Kennzahlen und die Messung generell dienen.
Denn, wie dieser Blog-Text hoffentlich gezeigt hat: ein Business Glossar entsteht nicht von alleine, sondern bedeutet und benötigt Anstrengung und Aufwand. Und der Nutzen soll sich dann eben auch einstellen – was man dann auch messen muss.
Die oben vorgestellten Kennzahlen – in diesem Fall für das Glossar – sind mal eine erste Idee, wie man den Nutzen bzw. den Reifegrad von Data Governance bzw. hier dem Business Glossar messen kann. In einem der nächsten Blog-Beiträge werde ich mal eine umfangreichere Darstellung von Data Governance-KPIs geben. Bis dahin…